

01The shift
From scripted bots to autonomous agents
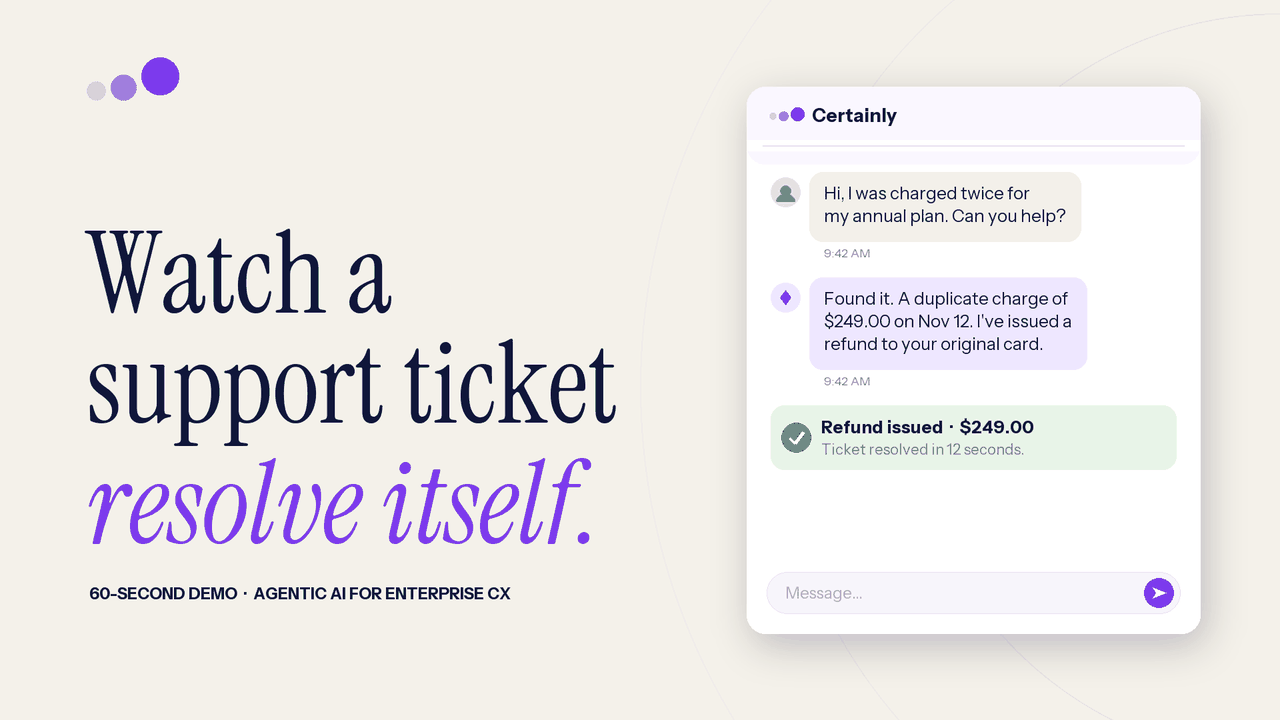
Agents reason about a goal, choose tools, and take real actions in your systems, instead of following brittle decision trees.
Decision trees, brittle flowsReasoning, tools, real actions
0-0%
Autonomous resolution on conversations legacy bots escalated


